Friday, March 30, 2007
Bangalore Barcamp 3
I'm off to Bangalore this evening to attend the third barcamp at bangalore. I'm hoping for some good discussion and meet up with interesting people. I'll post a roundup of the event when I get back on Monday.
Thursday, March 22, 2007
Little Green Guys With Guns
I found out about Little Green Guys With Guns, a play by email game through Ian Hickson. I played through the tutorial and it looked pretty fun, so I've joined the newbie game thats running. If you're into this sort of thing, take a look at LGGWG and join in. It should be fun!
Sunday, March 18, 2007
Python decorators and generators: An introduction
I gave an introduction to python decorators and generators at yesterdays ChennaiPy meet. I've uploaded the presentations to the files section of the yahoo group (OpenOffice 2 format).
Tuesday, March 13, 2007
More on python decorators
A few months ago, I wrote an article on Using python decorators to implement guards. When Parthan from ChennaiPy was preparing for talk on decorators due to be given at the FOSS event at NIT Calicut, he mailed me for a few more examples of decorators. He's put up the examples along with an explanation of each example over here. If you are looking to learn more about python decorators, check out the blog post.
Sunday, March 11, 2007
The beauty of clean URLs
One of the objectives when I was setting up the Silver Stripe website was to have clean URLs. If you notice, almost none of the URLs on the Silver Stripe website contain the filename or file extension within them. I'm using Apache's mod_rewrite to point the clean URL to the actual file on the filesystem.
Today, I'm happy I did. I recently changed over a few pages from static html to php, and a corresponding change in the filename. However, since the URLs don't point directly to the file on the filesystem, I didn't have to change any URL.
If you are working on a website, I highly recommend using mod_rewrite or equivalent to use clean URLs that are separated from the actual implementation.
There is a body of information on how to design URLs. Check these out for a start
Today, I'm happy I did. I recently changed over a few pages from static html to php, and a corresponding change in the filename. However, since the URLs don't point directly to the file on the filesystem, I didn't have to change any URL.
If you are working on a website, I highly recommend using mod_rewrite or equivalent to use clean URLs that are separated from the actual implementation.
There is a body of information on how to design URLs. Check these out for a start
Saturday, March 10, 2007
Broken statistics: Normalising test scores
The state government recently announced that a common entrance test for admission into engineering courses will be abolished and replaced by normalisation. You see, there are many different boards, each with its own tests of differing difficulties. We need a method for comparing the scores from different boards for processing admission to colleges.
Lets say that we have two boards, Board A and Board B. The scores in the two boards are as follows
Looking at the above scores, it seems that the test paper for Board A was a lot easier. If we compare the scores directly, Board A students have an unfair advantage. That's why we need to normalise the scores in order to properly judge the relative merits of the students from different boards.
The proposed normalisation scheme (according to the newspaper) is as follows:
Now we can see why this method is so broken. Although a casual glance tells us that Board B's test paper was a lot harder, the scores after normalisation have hardly changed! This is because one person got a good score of 98. This single data point is an exception to the rule, yet it has influenced the process so much as to render the normalisation completely meaningless.
This is an example of broken statistics. The top mark is usually an outlier and its a bad idea to calculate statistics of some data based on the outlier values.
I'm pretty amazed that they adopted this method of normalisation. Surely some statistician must have brought up this issue??
So what can be done?
I'm not a statistician, but here are some ideas that come to mind.
Fitting to a normal curve
How this works is to take the top mark and map it to 100, take the bottom score and map it to 0, and then map the intermediate scores based on a normal distribution with mean 50 and some experimentally obtained standard deviation. The two distributions can then be compared.
Drawbacks: This only works if the score distribution is normal! Usually it is not. The graph is generally skewed towards higher marks, as there are a lot more people passing the test than failing it. A common mistake is taking a non-normal distribution and fitting it to a normal curve.
Percentiles
Another scheme that is used is percentiles. The percentile is the percent of people who scored below you. So a 95 percentile means that 95% of the population who took the test are below you. Or in other words, you are in the top 5% of the population. Then, instead of comparing the absolute marks, you compare the percentiles.
This is like comparing rank, except that it normalises the fact that different number of students might have taken the two tests.
Drawbacks: A big drawback with percentile is that it can break near areas of high density. Take the above example again
As you can see, only 4 points separates the 0 percentile with 60 percentile. Of course, the effect is pronounced in this example because the sample size is so small. The same thing happens to a lesser degree in larger samples if the data is very dense in certain parts of the distribution.
Conclusion
Neither of the above solutions are particularly satisfying. Both introduce distortions of mapping one distribution onto another. In one case we are mapping a non-normal distribution to a normal one, in the other we are mapping it to a linear distribution.
The ideal solution would be to find out the actual distribution for test scores. Once that is done, both sets of scores can be equalised using the parameters of that distribution and compared. Since the distribution will be the same for both sets of test scores, the mapping will not introduce any distortion and the comparision will be fair.
Lets say that we have two boards, Board A and Board B. The scores in the two boards are as follows
| Board A | Board B |
| 100 | 98 |
| 100 | 83 |
| 98 | 82 |
| 95 | 81 |
| 93 | 80 |
Looking at the above scores, it seems that the test paper for Board A was a lot easier. If we compare the scores directly, Board A students have an unfair advantage. That's why we need to normalise the scores in order to properly judge the relative merits of the students from different boards.
The proposed normalisation scheme (according to the newspaper) is as follows:
- The ratio between the highest marks constitutes a multiplication factor
- This multiplication factor is applied to all the scores
| Board A | Board B | Normalised Board B |
| 100 | 98 | 98x(100/98) = 100 |
| 100 | 83 | 83x(100/98) = 84.7 |
| 98 | 82 | 83.7 |
| 95 | 81 | 82.7 |
| 93 | 80 | 81.6 |
Now we can see why this method is so broken. Although a casual glance tells us that Board B's test paper was a lot harder, the scores after normalisation have hardly changed! This is because one person got a good score of 98. This single data point is an exception to the rule, yet it has influenced the process so much as to render the normalisation completely meaningless.
This is an example of broken statistics. The top mark is usually an outlier and its a bad idea to calculate statistics of some data based on the outlier values.
I'm pretty amazed that they adopted this method of normalisation. Surely some statistician must have brought up this issue??
So what can be done?
I'm not a statistician, but here are some ideas that come to mind.
Fitting to a normal curve
How this works is to take the top mark and map it to 100, take the bottom score and map it to 0, and then map the intermediate scores based on a normal distribution with mean 50 and some experimentally obtained standard deviation. The two distributions can then be compared.
Drawbacks: This only works if the score distribution is normal! Usually it is not. The graph is generally skewed towards higher marks, as there are a lot more people passing the test than failing it. A common mistake is taking a non-normal distribution and fitting it to a normal curve.
Percentiles
Another scheme that is used is percentiles. The percentile is the percent of people who scored below you. So a 95 percentile means that 95% of the population who took the test are below you. Or in other words, you are in the top 5% of the population. Then, instead of comparing the absolute marks, you compare the percentiles.
This is like comparing rank, except that it normalises the fact that different number of students might have taken the two tests.
Drawbacks: A big drawback with percentile is that it can break near areas of high density. Take the above example again
| Score | Percentile |
| 98 | 80 |
| 83 | 60 |
| 82 | 40 |
| 81 | 20 |
| 80 | 0 |
As you can see, only 4 points separates the 0 percentile with 60 percentile. Of course, the effect is pronounced in this example because the sample size is so small. The same thing happens to a lesser degree in larger samples if the data is very dense in certain parts of the distribution.
Conclusion
Neither of the above solutions are particularly satisfying. Both introduce distortions of mapping one distribution onto another. In one case we are mapping a non-normal distribution to a normal one, in the other we are mapping it to a linear distribution.
The ideal solution would be to find out the actual distribution for test scores. Once that is done, both sets of scores can be equalised using the parameters of that distribution and compared. Since the distribution will be the same for both sets of test scores, the mapping will not introduce any distortion and the comparision will be fair.
Tuesday, March 06, 2007

Monday, March 05, 2007
Do you have your OpenID yet? — An OpenID Primer
OpenID is a technology that allows you to login to multiple sites using a single user name and password. The website needs to support OpenID login for this to work, but recently a number of websites have announced support for OpenID. With OpenID starting to get some traction, I decided to stop sitting on the fence and to see what it was all about.
When I started out, I was terribly confused about OpenID. It's actually really simple and straightforward. Hopefully this guide helps.
Getting an OpenID username and password
The first step was to get myself an OpenID account. This part confused me to start with because I assumed that there would be one centralised OpenID provider. Not so! OpenID is completely decentralised which means that there are a number of OpenID providers. You can create an OpenID account with any of them. After some poking around, I decided to create an account with claimID. You'll be asked to set a username and password for your account, and in a couple of minutes the account will be ready. Along with the account, you'll get a page that you can fill with links. Mine is here. The important part though is in the page source. Do a View Source on that page, and you get these headers:

We'll see how these headers are used later on.
Logging into an OpenID enabled site
Right, so we've got an OpenID login. How do we use this to login to an OpenID enabled website? Lets go through an example. We are going to use OpenID to log into Ma.gnolia. First, go to the site and select the option to login with OpenID. You will be asked to enter your OpenID URL. Thats right, you don't enter your user name and password here. Instead you enter a URL. In this case, thats the claimID URL that we saw before. Enter that URL as shown below and click the Login button.
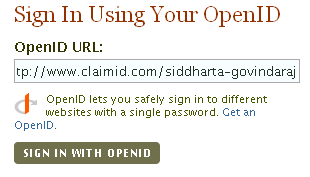
What Magnolia does is it retrieves the URL provided and reads the OpenID headers contained in it. Here it is again
The openid.server and openid.delegate fields tell the website which server to contact to handle the login. Magnolia then takes these bits of information and asks the server mentioned in the header to log in. You'll now be redirected to the login page on the OpenID server, where you'll be asked for a username and password. Enter the username and password that you set while creating your claimID account and click the Login button. The OpenID server will now verify your credentials and log you in. In this case, Mag.nolia is asking for some more information.
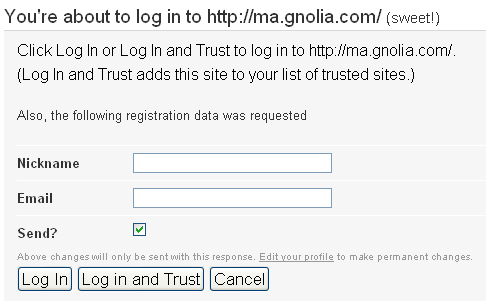
Fill up the form and you're done. There are two ways of logging in. "Log In" will just log you in normally, but will ask you for confirmation everytime you log in to the site. "Log In and Trust" will log you in and not ask for confirmation in the future. In any case, you can always change the settings later. Once you login, you'll be redirected back to the Ma.gnolia website to continue what you were doing. In the whole transaction, Ma.gnolia never finds out what your user name and password was. All they know is that the OpenID URL was validated correctly by the backend server.
Logging into another site
Let try it once more by logging into livejournal. First, select the option to login with OpenID.
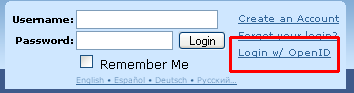
Next, enter your OpenID URL as before.

As before, livejournal contacts the OpenID server, but as we are already logged into that server, it doesn't ask us for entering the username and password again (Had you logged out of the OpenID server, it would have asked for the user name and password). Instead it jumps straight to the Log In confirmation screen. Click Log In and you're in. No account creation required! Pretty cool. All you need to remember is one user name and password and the URL to the page containing the OpenID headers.
OpenID delegation
Right, so you've got OpenID accounts at a number of sites, and one day claimID goes out of business. Have you lost all your login details at every website? Thats a scary thought. Luckily its all been taken care of. Enter OpenID delegation. Remember, you log into websites by entering a URL. The only purpose of that URL is to retrieve the OpenID headers. So, if you can create a page with the relevant OpenID headers, you can use that page as your OpenID login URL. Now, what I've done is to modify the blog template to add the OpenID headers to this page. Do a View Source on this blog, and you'll find these lines

If you're using claimID, you dont even need to figure out the code because they conveniently provide you with the code snippet to paste into your own blog or website. I can now login using my blog address as the OpenID URL.

Lets say I create accounts on websites using this URL. As far as the website is concerned, it is the OpenID URL which is your identifier, not the backend details. So if claimID were to go out of business, or for any reason I wanted to switch, all I need to do is create an OpenID account at another provider and change the headers on this page to point to the new provider's details. When I login at a website, the website will now contact the new backend provider to log me in. My login URL at the website remains unchanged! Neat!
Security with OpenIDs
One of the big misconceptions that I had was that OpenID was a centralised system for authentication around the web (remember Microsoft Passport? Google is getting there too). It always scared me that if one account got compromised and someone figured out the username and password, it put all the other websites at risk. Nothing of the sort.
One thing to point out. Login details are stored on the backend OpenID server. The websites never get to know it. Even if a website gets compromised, cracked, whatever, and data gets stolen, your login details are safe. So OpenID is actually quite a bit safer in that respect.
Still, your login details may get compromised by any number of other means. Here are some things you can do to make it more secure.
First, OpenID delegation is a great thing, so set it up ASAP. If your user name and password were to get compromised, all you need to do is to create a new account with claimID (or any provider) and setup the delegation to the new account. The next time anyone uses your URL to log in, they will need to enter the NEW user name and password. Cool!
Second, nothing stops you from creating two or three OpenID accounts. You can then use one for say, all the social networking sites, another for your blogs and so on. If one were to get compromised, damage is only restricted to the sites that share the same OpenID account.
Conclusion
OpenID is pretty cool. It's becoming big. Get yourself an account and start playing around with it. Run a website? Think about supporting OpenID logins.
I've only been using OpenID for a couple of days, so if you have any feedback, comments or corrections, I would love to hear it.
When I started out, I was terribly confused about OpenID. It's actually really simple and straightforward. Hopefully this guide helps.
Getting an OpenID username and password
The first step was to get myself an OpenID account. This part confused me to start with because I assumed that there would be one centralised OpenID provider. Not so! OpenID is completely decentralised which means that there are a number of OpenID providers. You can create an OpenID account with any of them. After some poking around, I decided to create an account with claimID. You'll be asked to set a username and password for your account, and in a couple of minutes the account will be ready. Along with the account, you'll get a page that you can fill with links. Mine is here. The important part though is in the page source. Do a View Source on that page, and you get these headers:

We'll see how these headers are used later on.
Logging into an OpenID enabled site
Right, so we've got an OpenID login. How do we use this to login to an OpenID enabled website? Lets go through an example. We are going to use OpenID to log into Ma.gnolia. First, go to the site and select the option to login with OpenID. You will be asked to enter your OpenID URL. Thats right, you don't enter your user name and password here. Instead you enter a URL. In this case, thats the claimID URL that we saw before. Enter that URL as shown below and click the Login button.

What Magnolia does is it retrieves the URL provided and reads the OpenID headers contained in it. Here it is again
The openid.server and openid.delegate fields tell the website which server to contact to handle the login. Magnolia then takes these bits of information and asks the server mentioned in the header to log in. You'll now be redirected to the login page on the OpenID server, where you'll be asked for a username and password. Enter the username and password that you set while creating your claimID account and click the Login button. The OpenID server will now verify your credentials and log you in. In this case, Mag.nolia is asking for some more information.

Fill up the form and you're done. There are two ways of logging in. "Log In" will just log you in normally, but will ask you for confirmation everytime you log in to the site. "Log In and Trust" will log you in and not ask for confirmation in the future. In any case, you can always change the settings later. Once you login, you'll be redirected back to the Ma.gnolia website to continue what you were doing. In the whole transaction, Ma.gnolia never finds out what your user name and password was. All they know is that the OpenID URL was validated correctly by the backend server.
Logging into another site
Let try it once more by logging into livejournal. First, select the option to login with OpenID.

Next, enter your OpenID URL as before.

As before, livejournal contacts the OpenID server, but as we are already logged into that server, it doesn't ask us for entering the username and password again (Had you logged out of the OpenID server, it would have asked for the user name and password). Instead it jumps straight to the Log In confirmation screen. Click Log In and you're in. No account creation required! Pretty cool. All you need to remember is one user name and password and the URL to the page containing the OpenID headers.
OpenID delegation
Right, so you've got OpenID accounts at a number of sites, and one day claimID goes out of business. Have you lost all your login details at every website? Thats a scary thought. Luckily its all been taken care of. Enter OpenID delegation. Remember, you log into websites by entering a URL. The only purpose of that URL is to retrieve the OpenID headers. So, if you can create a page with the relevant OpenID headers, you can use that page as your OpenID login URL. Now, what I've done is to modify the blog template to add the OpenID headers to this page. Do a View Source on this blog, and you'll find these lines

If you're using claimID, you dont even need to figure out the code because they conveniently provide you with the code snippet to paste into your own blog or website. I can now login using my blog address as the OpenID URL.

Lets say I create accounts on websites using this URL. As far as the website is concerned, it is the OpenID URL which is your identifier, not the backend details. So if claimID were to go out of business, or for any reason I wanted to switch, all I need to do is create an OpenID account at another provider and change the headers on this page to point to the new provider's details. When I login at a website, the website will now contact the new backend provider to log me in. My login URL at the website remains unchanged! Neat!
Security with OpenIDs
One of the big misconceptions that I had was that OpenID was a centralised system for authentication around the web (remember Microsoft Passport? Google is getting there too). It always scared me that if one account got compromised and someone figured out the username and password, it put all the other websites at risk. Nothing of the sort.
One thing to point out. Login details are stored on the backend OpenID server. The websites never get to know it. Even if a website gets compromised, cracked, whatever, and data gets stolen, your login details are safe. So OpenID is actually quite a bit safer in that respect.
Still, your login details may get compromised by any number of other means. Here are some things you can do to make it more secure.
First, OpenID delegation is a great thing, so set it up ASAP. If your user name and password were to get compromised, all you need to do is to create a new account with claimID (or any provider) and setup the delegation to the new account. The next time anyone uses your URL to log in, they will need to enter the NEW user name and password. Cool!
Second, nothing stops you from creating two or three OpenID accounts. You can then use one for say, all the social networking sites, another for your blogs and so on. If one were to get compromised, damage is only restricted to the sites that share the same OpenID account.
Conclusion
OpenID is pretty cool. It's becoming big. Get yourself an account and start playing around with it. Run a website? Think about supporting OpenID logins.
I've only been using OpenID for a couple of days, so if you have any feedback, comments or corrections, I would love to hear it.
Subscribe to:
Posts (Atom)